

This post has been modified from its original form on woodpeckR.
Problem
Last month, I was super excited to discover the case_when() function in dplyr. But when I showed my blog post to a friend, he pointed out a problem: there seemed to be no way to specify a “background” case, like the “else” in ifelse().

In the previous post, I gave an example with three outcomes based on test results. The implication was that there would be roughly equal numbers of people in each group. But what if the vast majority of people failed both tests, and we really just wanted to filter out the ones who didn’t?
Context
Let’s say I’m analyzing morphometric data for the penguins in the Palmer Penguins dataset. I conduct a principal components analysis.
# Load the penguins data
library(palmerpenguins)
library(dplyr) # for pipe and case_when and mutate etc.
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionlibrary(tibble) # for rownames_to_column
library(ggplot2) # for plotting
# Conduct Principal Components Analysis (PCA)
pca <- prcomp(~bill_length_mm + bill_depth_mm +
flipper_length_mm + body_mass_g, data = penguins)
# Label pca score rows to prepare for join with penguins.
components <- pca$x %>%
as.data.frame() %>%
rownames_to_column("id")
# Join pca scores to penguins
penguins <- penguins %>%
rownames_to_column("id") %>%
left_join(components, by = "id")# Take a peek at the data:
penguins %>%
as.data.frame() %>%
head() # now the PC scores are joined onto the penguins data, so I can use it in plotting. id species island bill_length_mm bill_depth_mm flipper_length_mm
1 1 Adelie Torgersen 39.1 18.7 181
2 2 Adelie Torgersen 39.5 17.4 186
3 3 Adelie Torgersen 40.3 18.0 195
4 4 Adelie Torgersen NA NA NA
5 5 Adelie Torgersen 36.7 19.3 193
6 6 Adelie Torgersen 39.3 20.6 190
body_mass_g sex year PC1 PC2 PC3 PC4
1 3750 male 2007 -452.0232 13.336636 -1.14798019 -0.3534919
2 3800 female 2007 -401.9500 9.152694 0.09037342 -1.0483310
3 3250 female 2007 -951.7409 -8.261476 2.35184450 0.8417657
4 NA <NA> 2007 NA NA NA NA
5 3450 female 2007 -751.8127 -1.975922 4.81117040 2.1800839
6 3650 male 2007 -551.8746 3.343783 1.11849344 2.7060578After running the PCA, I make a plot of the 2nd and 3rd principal components that looks like this:
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).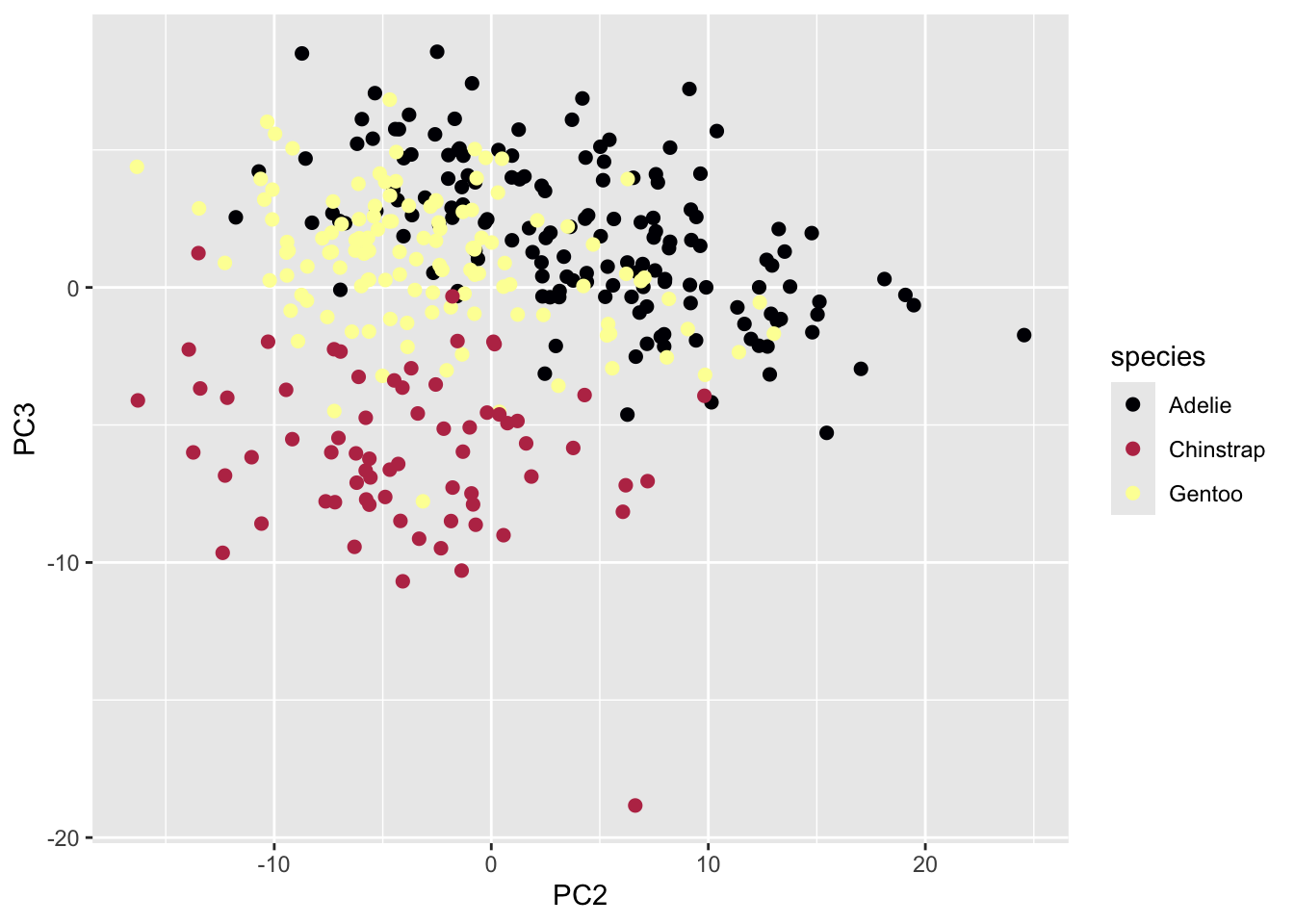
Before continuing my analysis, I wanted to take a closer look at a few points that look like they might be outliers. Specifically, I’m interested in the Adelie point that has a PC2 value greater than 20, and the Chinstrap point that has a PC3 value less than -15. I’m also slightly worried about the two points that have a PC2 value below -15, but they aren’t quite as far out, so I want to classify them separately.
To figure out which penguins to look at in the data, I will have to pull out rows based on their scores on the PC2 and PC3 axes.
Solution
I decide to add a column called investigate to my data, set to either ‘investigate’, ‘maybe’ or ‘no’ depending on whether the observation in question needs to be checked.
This is a great use for my new friend case_when()! I’ll approach it like this:
penguins <- penguins %>%
mutate(investigate = case_when(PC2 > 20 | PC3 < -15 ~ "investigate",
PC2 < -15 ~ "maybe",
TRUE ~ "no"))What’s up with that weird TRUE ~ "no" line at the end of the case_when() statement? Basically, the TRUE is the equivalent of an else. It translates, roughly, to “assign anything that’s left to ‘no.’”
Why ‘TRUE’, not ‘else’?
I don’t love the choice of TRUE here–I think the syntax is pretty confusing, and it’s something I had to memorize long before I understood the logic behind it.
Basically, case_when() works by checking each of your ‘cases’ (conditions, if-statements) in order. For each row of the data frame, it checks the first case, and applies the resulting assignment if the row meets that case. If the row does not meet the first case, the function moves on to the second case, then the third, and on and on until it finds a case that evaluates to TRUE for that row.
So, when you want to write an “else” condition, you write TRUE as a catchall. TRUE will always evaluate to TRUE, so all rows that are left over after failing the first however many conditions will all “pass” that last condition and will be assigned to your desired “else” value.
Because of this, order matters! If I had started off with the TRUE ~ “ok” statement and then specified the other conditions, my code wouldn’t have worked: everything would just get assigned to “no”.
The dark side of the TRUE condition
You might be wondering what would happen if we omitted the TRUE condition. In part 1 of my case_when() explanation
Citation
BibTeX citation:
@online{gahm2019,
author = {Gahm, Kaija},
title = {If Ifelse() Had More If’s (Case\_when(), Part 2)},
date = {2019-11-22},
url = {https://kaijagahm.github.io/posts/2019-11-22-if-ifelse-had-more-ifs-and-an-else},
langid = {en}
}
For attribution, please cite this work as:
Gahm, Kaija. 2019. “If Ifelse() Had More If’s (Case_when(), Part
2).” November 22. https://kaijagahm.github.io/posts/2019-11-22-if-ifelse-had-more-ifs-and-an-else.